Back then 2021, Sanjay just joined Tiket and reviewed the latency on our website. He found an interesting problem that nobody had said before. He said, “I don’t understand why our microservices connect with the monolith service using the public domain.” At that point, I didn’t understand why he said that. What I know, if we want to connect with the monolith service, the typical URL we use will be http://tiket.com/x/y/z. Once again, He said, “Nobody uses the public domain for communicating between services in the internal system.” Then that’s the time we learnt our lesson for network topology.
I don’t know if I used the right term for network topology LOL. What I want to share here is more about what you need to know about the network infrastructure in your company and how the client can connect to your backend. If it’s a simple website like a personal WordPress site (like my website, LOL), then you can do it with simple web hosting. However, if we discuss an enterprise company like Tiket, then understanding how the infrastructure network would be beneficial to unleash the full potential of your service.
The first lesson will be the load balancer. Most of the distributed systems use a load balancer. In Tiket, we use HAProxy. Please don’t ask me why we chose that LOL. Back again to Sanjay, when he joined, he always asked HAProxy, and somehow, he seems a little irritated with this thing. Before I worked with FinOps, I didn’t know why; however, once I worked with FinOps, I clearly got why he’s irritated with that. The problem was actually not in the technology itself, but in how we manage that thing and how we convey to the people who use it on a daily.
As I mentioned earlier, the communication between the internal service should use private network url, it should not use a public domain like https://tiket.com/x/y/z. If we do this, the illustration will be like this:
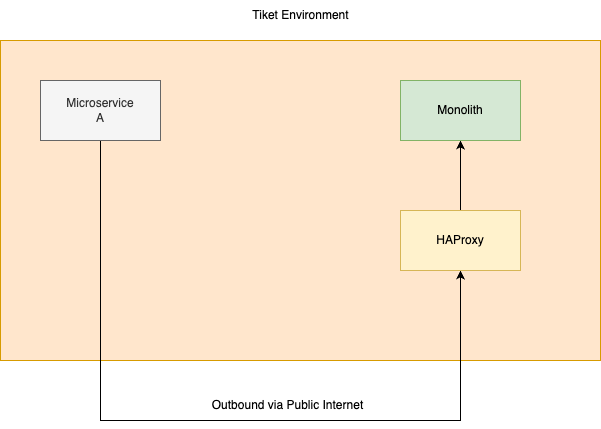
If you see that, then people will ask, Why do we need to go over the public internet to call the service that actually runs in the same environment? That’s why Sanjay was mad, and it’s very logical. The way we should call should be a direct call through the HAProxy itself, so that it won’t go to the public internet. It should be an internal network call.
Disclaimer: If you look at the graph, I have oversimplified the architecture, which is actually a complicated setup in the current setup.
Now, after Sanjay instructed to call the Monolith via HAProxy, the graph will be like this.
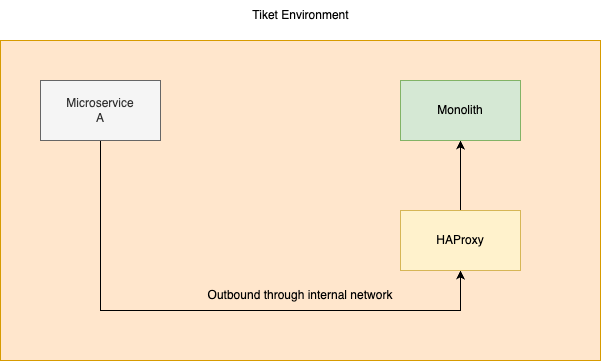
If you asked me, was there any improvement or not, then I would say I didn’t know LOL. Because at that time, we hadn’t monitored the performance of outbound. That’s why kind of things like this, we were never concerned about.
Next lesson, as most of the Tiket service is already deployed in Kubernetes, there will be another network hop before reaching the service itself. Previously, we deployed our service in a VM. in order to communicate between services, we can directly call through HAProxy. So this is the illustration:
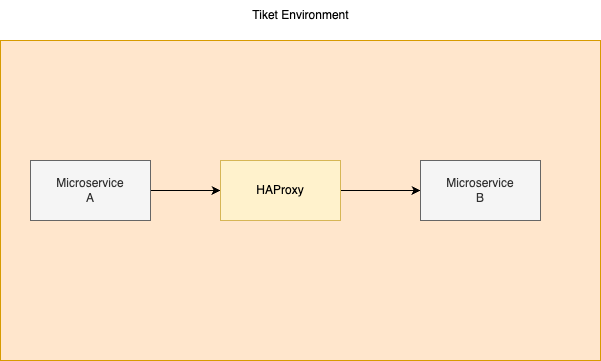
Now, due to this routing, we had a problem because services running in the same clusters tried to call them through HAProxy.
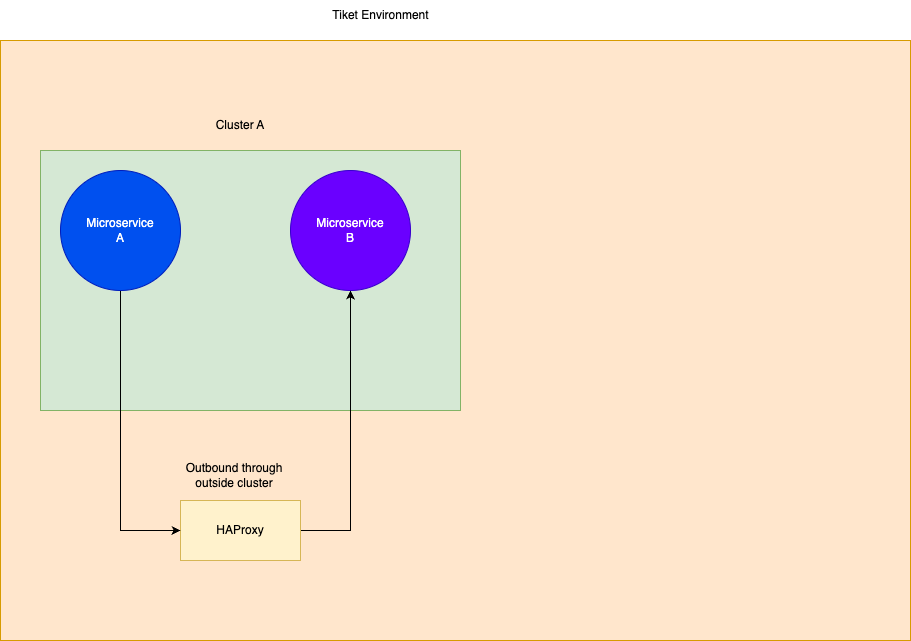
Now imagine you’re in the same house, but in order to talk with your neighbour in the different room, you need to go outside the house, and then back again to the house and talk. This was completely inefficient because it added another network hop. At the same time, Kubernetes had ingress to work as a load balancer like HAProxy, so you need to spawn 2 machines at the same time, which were HAProxy and the Ingress controller itself. I remember when one of my former colleagues in my team asked, “Why do we still need to call HAProxy when we already moved to Kubernetes? We should call them directly through ingress or even via local DNS, which is FQDN“. Once again, at that point, I still didn’t know what the difference was, but once I knew, that’s one of the stupidest things I’ve ever done lol.
In order to solve this complex routing problem, we need to identify several things:
- If the downstream runs in the same cluster as the upstream, then we will use the FQDN to communicate between the services.
- If the downstream runs in the separate cluster as the upstream, then we will use the ingress to communicate between the services.
- If the downstream runs in the VM, then we will use HAProxy to communicate between the services.
Now, what’s the benefit of understanding the network topology in terms of FinOps?
- Reduce the network hop. Clearly, if we know how the service communicates, then we should aim for the shortest path to reach the downstream.
- Lower the latency. Since the service communication doesn’t need to go multiple hops, it means it can receive the response in less time. Based on the experience, the latency may be lowered up to 10-50ms per call.
- Reduce the CPU usage for the upstream service. As the I/O will reduce due to the service being able to connect faster, the service will not need to work so much. Based on the experience, it can reduce the CPU usage from 1-5%.
- Reduce the spec for HAProxy. Once you know that most of the services are running in Kubernetes, clearly you don’t need to have a high spec for the HAProxy anymore.
- Reduce the spec for Ingress. For every service running in the same cluster, clearly, you don’t need to have a high spec for the Ingress controller anymore.
Learn from this kind of experience, I worked with the DevOps for another new project. We built the new cluster with the Envoy. As there is news that ingress-nginx will be deprecated soon, I believe, the movement to Envoy would be a good choice if you still use ingress. The good thing about Envoy is that they have Envoy Gateway, which we can say is the extension of the Envoy Proxy itself. So you can kill 2 birds with one stone.
Now you can start asking your DevOps how the network architecture in your company is, LOL.